Ok, vamos finalmente para a terceira parte sobre Redes Neurais (e também, aonde será apresentado o código completo de uma rede neural em Ruby). Este post será sobre treinamento de redes neurais, especificamente sobre o treinamento dos pesos que saem dos neurônios de entrada e vão para os neurônios ocultos da rede. Antes de mais nada, vamos relembrar nosso desenho da rede neural:

Já vimos no post anterior que para achar o valor que MAXIMIZA a função de custo, usamos o métoodo chamado de “gradiente”. O método “gradiente” usa derivadas parciais, e como vamos achar o valor de um peso que sai do neurônio de entrada para o neurônio da camada oculta, precisamos calcular a derivada parcial da função de custo em relação a um destes pesos. Vamos usar o “peso_a1_b2” para este exemplo.
Antes de mais nada, vamos relembrar todas as contas que fazemos para nossa rede neural. Para tal, eu vou usar a notação “peso_ax_by” para indicar o peso que sai do neurônio “ax” e vai para o neurônio “by”. Note que NÃO EXISTE “peso_a1_b1”, porque o neurônio “b1” é o “bias”, logo o valor dele é sempre “1” (e não faria sentido calcular um valor se ele vai descartá-lo e usar “1”, no fim das contas). Sabemos que o valor de um neurônio oculto é a soma de todos os valores dos neurônios de entrada (multiplicados por seus devidos pesos) e aplicadas uma “função de ativação” (que no nosso caso, é a “Tangente Hiperbólica”). Eu vou chamar de “b_sem_ativacao_x” o valor desta soma dos neurônios de entrada, ANTES de se aplicar a função de ativação. Logo, nossas contas são:
Na conta acima, “N” é o número de exemplos (dados de treinamento) que passamos para nossa rede. Repare que na função de custo, há também uma “soma de somas”, ou seja, calcula-se o erro de UM exemplo (soma que vai de i=1 até i=2, ou seja, nossos dois neurônios de saída) e soma-se com os erros de TODOS os exemplos, tirando-se a média (1/2N) em seguida. Para facilitar nosso cálculos, vamos ajustar um pouco a função de custo:

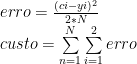
Porque uma derivada de uma somatória é a mesma coisa que a somatória das derivadas, então tudo fica mais fácil. Vamos às derivações então:
Vendo as contas, é fácil ver que o “peso_a1_b2” não aparece na função de custo: ele aparece na função de “b_antes_da_ativacao_2”. Isso significa que teremos que aplicar a “regra da cadeia” de novo, em nossas contas. Então, vamos lá: a regra é que para derivar “custo” em relação a “peso_a1_b2”, temos que ir “caminhando” em nossas funções até achar a função em que “peso_a1_b2” aparece:


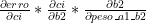
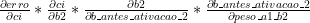
Logo, achamos nossa derivação. Calculando as derivadas parciais:

Se substituirmos isso em nossa somatória, temos:
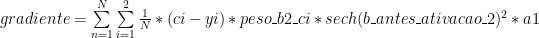
Vamos agora “quebrar” essa somatória em alguns pedaços: sabemos que a parte interna é o erro de UM exemplo (como é a derivada, então é o gradiente de UM exemplo). Vamos expandir a somatória para, ao invés de usarmos “ci” e “yi”, usarmos “c2”, “c2” e “y1”, “y2”:

Parece que ficou mais complexo, mas temos muita coisa repetida nessa conta. Vamos colocar tudo o que é repetido em evidência. Podemos fazer a partir da simples regra:
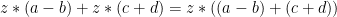

Parece mais interessante! O gradiente de um exemplo, nesse caso, foi representado através de uma sequencia de multiplicações. Em um dos casos (gradiente_um_exemplo1), duas multiplicações somadas. Não vou me extender muito mais nesse assunto, mas a derivada do peso_a3_b4, por exemplo, é:

Generalizando: Derivada do peso_ai_bj é: sech(b_antes_ativacao_j)2 * ai * (peso_bj_c1 * (c1 – y1) + peso_bj_c2 * (c2 – y2))
Interessante que isso é possível de representar como uma multiplicação de matrizes: como é possível ver, certos elementos são iguais. Logo:

Relembrando, nossa matriz de pesos dos neurônios ocultos até os neurônios de saída:

É possível ver que nunca multiplicaremos algo pelo peso_b1_c1 ou pelo peso_b1_c2, já que não temos “peso_ai_b1”. Logo, vamos remover esta linha de cima, e multiplicar o resultado pela nossa matriz de erros:

Opa, começou a interessar: nossa matriz já é equivalente ao “gradiente_um_peso1” e “gradiente_um_peso_2” (primeira e última linhas). Temos agora que multiplicar pela derivada da nossa função de ativação (no caso, sech(elemento)2), e aí, só vai faltar multiplicar pelo ai, que de certa forma, sai um pouco da fórmula. Uma forma de multiplicar a derivada é multiplicarmos elemento a elemento. Claro que, no caso, o parâmetro que passaremos para a secante hiperbólica (a derivada da função de ativação) é o que entraria nos neurônios “B” ANTES de passar pela função de ativação. Vamos, por hora, fazer de conta que temos essa informação (no nosso código, na primeira parte deste post, temos o código output = input_with_bias * weights. Seria esse valor que usaríamos em nossa matriz. Repare que não precisamos “retirar nenhuma linha”, porque olhando para o desenho da rede neural, fica claro que não temos nenhum peso saindo do neurônio ai para o neurônio b1, logo nossa matrix teria o número certo de linhas):

Bom, agora falta multiplicar por ai. O processo é bem simples: os pesos de A para B estão organizados assim:
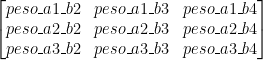
Logo, vemos que temos que ter uma matriz formada da seguinte maneira: na primeira linha, temos a1 multiplicando todas as linhas da nossa matrix gradiente_com_sech (cada linha vai numa coluna), na segunda, a2, e na terceira, a3. Nota-se que quem define quantas linhas nossa matriz de saída é a matriz “a”, ou a matriz de entrada com o neurônio “bias”.

E quem define nossas “colunas” é a nossa matriz gradiente_com_sech, obviamente transposta:

Simplifiquei a matriz senão não temos espaço na página. Por fim, se multiplicarmos as duas:

Vamos pegar, então, essa matriz na posição 1,1 (equivalente ao peso_a1_b2): a conta ficaria a1 * gradiente_com_sech_2, que é a1 * sech2(b_antes_ativacao_2) * (peso_b2_c1 * (c1 – y1) + peso_b2_c2 * (c2 – y2)). Conforme vimos, isso é equivalente ao gradiente que calculamos. Se usarmos a posição 3,3, teremos o outro gradiente. Isto é para apenas 1 exemplo, mas basta dividir todos os elementos da matriz pelo número de exemplos, que teremos o gradiente calculado corretamente… então, no código de cálculo de gradiente (continuando do post anterior) temos:
def calculate_gradient(input, input_weights, hidden_weights, output_matrix)
hidden_layer_input = calculate_neuron_activation(input, input_weights)
output = calculate_neuron_activation(hidden_layer_input, hidden_weights)
#Custo desta solução:
size = output_matrix.row_size
error = output - output_matrix
squared_error = error.map { |e| e * e }
mean_squared_error = squared_error.to_a.flatten.inject(0) { |r, e| r + e } / (2 * size)
#Cálculo dos gradientes (oculta -> saída)
hidden_layer_input_with_bias = hidden_layer_input.to_a.map { |x| [1] + x }
hidden_layer_input_with_bias = Matrix[*hidden_layer_input_with_bias]
gradient1 = (error.transpose * hidden_layer_input_with_bias).transpose / size
#Cálculo dos gradientes (entrada -> oculta)
hidden_weights_chopped = Matrix[*hidden_weights.to_a[1..-1]]
gradient2 = hidden_weights_chopped * error.transpose
#Preparando uma matriz sem a função de ativação
input_with_bias = input.to_a.map { |x| [1] + x }
input_with_bias = Matrix[*input_with_bias]
hidden_layer_input_without_activation = (input_with_bias * input_weights).transpose
#Calculando a derivada da função de ativação. Como não temos, em Ruby, uma função
#Math.sech, basta saber que 1-tanh(elemento)^2 é a mesma coisa que sech(2)^2
derivatives = hidden_layer_input_without_activation.map { |e| 1 - Math.tanh(e) ** 2 }
#Multiplicar elemento a elemento é meio chato. Estamos aqui transformando
#o "map" num enumerable, para poder multiplicar com o outro elemento
mapped = gradient2.enum_for(:map)
derivatives = derivatives.to_a.flatten
gradient2 = mapped.with_index { |element, i| element * derivatives[i] }
#Multiplicação pelos neurônios de entrada
gradient2 = input_with_bias.transpose * gradient2.transpose
#Divisão pelo número de elementos de treinamento
gradient2 = gradient2 / size
{
:cost => mean_squared_error,
:gradient_inputs => gradient2,
:gradient_hidden => gradient1
}
end
Bom, calculamos a função de custo e todos os gradientes, finalmente. O que fazer, agora? Existem muitas abordagens para treinamento, mas uma que funciona relativamente bem é: primeiro, fixamos uma constante “alfa” que define o quanto o gradiente vai ser atenuado (isso é importante, já que nem sempre subtrair o gradiente leva a uma solução menor). Depois, prosseguimos com o treinamento até vermos que a rede atingiu um erro pequeno. Se o erro aumentar, de uma interação até a outra, diminuimos o “alfa”. Vamos então a essa abordagem:
last_weights = [ input_weights, hidden_weights ]
last_cost = Float::MAX
alpha = 2
while(true)
gradients = calculate_gradient(input_matrix, input_weights, hidden_weights, output_matrix)
if gradients[:cost] < last_cost
last_weights = [ input_weights, hidden_weights ]
input_weights -= alpha * gradients[:gradient_inputs]
hidden_weights -= alpha * gradients[:gradient_hidden]
else
#Reseta os pesos para o mesmo valor da iteração anterior
input_weights, hidden_weights = last_weights
alpha *= 0.8 #Baixa o alfa em 20%
end
last_cost = gradients[:cost]
puts "Custo Atual: #{gradients[:cost]}"
break if gradients[:cost] < 0.04 #Nosso custo mínimo é 0.04
end
Pronto. Com esse código, a rede é treinada. Logo, o código completo da rede neural, com treinamento e predição, é:
require "matrix"
string = File.read('iris.data').strip.split("\n")
output = []
data = string.map do |line|
line = line.split(",")
output << case(line.last)
when /setosa/i then [1, 0, 0]
when /versicolor/i then [0, 1, 0]
else [0, 0, 1]
end
line[0..3].map { |e| e.to_f }
end
input_matrix = Matrix[*data]
output_matrix = Matrix[*output]
def initial_weights(rows, cols)
weights = 1.upto(rows).map do
1.upto(cols).map do
rand / 10 - 0.05
end
end
Matrix[*weights]
end
def activation_function(x)
Math.tanh(x)
end
def activation_derivative(x)
1 - (Math.tanh(x) ** 2)
end
input_weights = initial_weights(5, 8)
hidden_weights = initial_weights(9, 3)
def calculate_neuron(input, weights)
input_with_bias = input.to_a.map { |x| [1] + x }
input_with_bias = Matrix[*input_with_bias]
input_with_bias * weights
end
def calculate_neuron_activation(input, weights)
output = calculate_neuron(input, weights)
output.map { |element| activation_function(element) }
end
def dot_multiply(m1, m2)
result = m1.to_a.zip(m2.to_a).map do |row1, row2|
row1.zip(row2).map do |e1, e2|
e1 * e2
end
end
Matrix[*result]
end
lastcost = 100
alpha = 0.1
lamb = 1
class Matrix
def size
[row_size, column_size]
end
end
def calculate_gradient(input, input_weights, hidden_weights, output_matrix)
hidden_layer_input = calculate_neuron_activation(input, input_weights)
output = calculate_neuron_activation(hidden_layer_input, hidden_weights)
#Custo desta solução:
size = output_matrix.row_size
error = output - output_matrix
squared_error = error.map { |e| e * e }
mean_squared_error = squared_error.to_a.flatten.inject(0) { |r, e| r + e } / (2 * size)
#Preparando uma matriz sem a função de ativação
input_with_bias = input.to_a.map { |x| [1] + x }
input_with_bias = Matrix[*input_with_bias]
hidden_layer_input_without_activation = (input_with_bias * input_weights).transpose
#Cálculo dos gradientes (oculta -> saída)
hidden_layer_input_with_bias = hidden_layer_input.to_a.map { |x| [1] + x }
hidden_layer_input_with_bias = Matrix[*hidden_layer_input_with_bias]
gradient1 = (error.transpose * hidden_layer_input_with_bias).transpose / size
#Cálculo dos gradientes (entrada -> oculta)
hidden_weights_chopped = Matrix[*hidden_weights.to_a[1..-1]]
gradient2 = hidden_weights_chopped * error.transpose
#Calculando a derivada da função de ativação. Como não temos, em Ruby, uma função
#Math.sech, basta saber que 1-tanh(elemento)^2 é a mesma coisa que sech(2)^2
derivatives = hidden_layer_input_without_activation.map { |e| 1 - Math.tanh(e) ** 2 }
#Multiplicar elemento a elemento é meio chato. Estamos aqui transformando
#o "map" num enumerable, para poder multiplicar com o outro elemento
mapped = gradient2.enum_for(:map)
derivatives = derivatives.to_a.flatten
gradient2 = mapped.with_index { |element, i| element * derivatives[i] }
#Multiplicação pelos neurônios de entrada
gradient2 = input_with_bias.transpose * gradient2.transpose
#Divisão pelo número de elementos de treinamento
gradient2 = gradient2 / size
{
:cost => mean_squared_error,
:gradient_inputs => gradient2,
:gradient_hidden => gradient1
}
end
last_weights = [ input_weights, hidden_weights ]
last_cost = Float::MAX
alpha = 2
while(true)
gradients = calculate_gradient(input_matrix, input_weights, hidden_weights, output_matrix)
if gradients[:cost] < last_cost
last_weights = [ input_weights, hidden_weights ]
input_weights -= gradients[:gradient_inputs].map { |e| e * alpha }
hidden_weights -= gradients[:gradient_hidden].map { |e| e * alpha}
else
#Reseta os pesos para o mesmo valor da iteração anterior
input_weights, hidden_weights = last_weights
alpha *= 0.8 #Baixa o alfa em 20%
end
last_cost = gradients[:cost]
puts "Custo Atual: #{gradients[:cost]}"
break if gradients[:cost] < 0.04
end
def predict(input, input_weights, hidden_weights)
hidden_layer_input = calculate_neuron_activation(input, input_weights)
calculate_neuron_activation(hidden_layer_input, hidden_weights)
end
def interpret_result(output)
output.to_a.map do |e1, e2, e3|
if e1 > e2 && e1 > e3
"Setosa"
elsif e2 > e1 && e2 > e3
"Versicolor"
else
"Virginica"
end
end
end
hidden_layer_input = calculate_neuron_activation(input_matrix, input_weights)
output = calculate_neuron_activation(hidden_layer_input, hidden_weights)
puts interpret_result(output)
Por fim: não se costuma usar todo o conjunto de dados para treinamento. Costuma-se dividir o conjunto em dois, um de treinamento e um de validação (normalmente, divide-se 70% – 30%, ou 60% – 40%). O de validação serve, principalmente, para identificar se a predição conseguiu generalizar a regra corretamente, e não ficou “viciada” no conjunto de dados que está sendo usado. Outra coisa, estamos re-calculando muita coisa, mas corrigir este código fica como um exercício para o leitor!