No post anterior, vimos como montar a estrutura de uma rede neural. Neste post, veremos como fazer o treinamento dos pesos, para que a rede generalize nossos exemplos de teste e seja capaz de classificar exemplos que ainda não foram vistos. Num primeiro momento, vamos relembrar o desenho de uma rede neural:

Para facilitar, deixei um nome para cada neurônio (nota: provavelmente vocês não vão encontrar essa forma de nomear os neurônios em lugar algum-eu coloquei essa nomenclatura mais para facilitar o post do que para ser uma abordagem matemática mesmo). Os neurônios “a1” e “b1” são “bias”, conforme vimos no post anterior, e os neurônios “c1” e “c2” são os neurônios de saída. Note que este desenho de rede neural não representa nossa rede neural, pois nossa rede neural precisaria de 5 neurônios de entrada e 3 de saída. Bom, conforme vimos no post anterior, num primeiro momento os pesos sinápticos (as linhas ligando os neurônios, representadas pelas matrizes “input_weights” e “hidden_weights” no post anterior) são aleatórios, o que significa que a rede possuirá comportamento aleatório. A partir deste ponto, temos que alterar os pesos para tentar chegar num resultado melhor da rede. Para tal, precisamos de uma função que nos mostre quão bom é a solução atual: uma “função de custo”.
A função de custo, de uma rede neural, sempre se baseia no seguinte: “o que saiu da rede é parecido com o que eu esperava?”. Por exemplo, a rede trouxe a saída 0.2, mas eu esperava 1.0. Isso significa que a rede “errou” por 0.8 pontos, ou seja, 1.0 – 0.8. Porém, eu preciso fazer uma média de todos os exemplos para calcular esses “erros”, logo eu preciso de uma função que me retorne sempre um valor positivo. Uma alternativa é o “erro quadrático médio”, ou seja: SOMA_TODOS_EXEMPLOS((saida_rede – saida_esperada) ^ 2) / numero_exemplos. Para facilitar algumas contas, ao invés de dividir entre o numero_exemplos, vamos dividir por numero_exemplos * 2. Na fórmula abaixo, se tivermos 200 exemplos, e duas saídas, teremos:
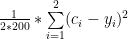
Agora, de posse de uma função de custo, podemos usar algum algoritmo para minimizar este custo alterando os pesos da rede. Podemos, por exemplo, usar algoritmo genético, mas no treinamento de redes neurais normalmente se usa o algoritmo “backpropagation”. O único pré-requisito do back-propagation é que todas as funções (desde as funções de ativação até as funções de custo) não possuam valores no qual não possuem resultado (ou, em um linguajar mais técnico, elas devem ser “deriváveis em todos os pontos”).
A idéia do backpropagation é simples: existe uma função matemática chamada “gradiente”, que indica para onde a função tem seu maior custo. Ou seja, se calcularmos o “gradiente”, acharemos qual o valor que MAXIMIZA a função de custo. Como, claramente, não é isto que desejamos, vamos SUBTRAIR este gradiente dos nossos pesos. O “gradiente” consiste em calcular derivadas parciais (se eu tiver uma função que possui X, Y, e Z, e quiser saber qual é o “X” que maximiza o valor da função, eu calculo uma derivada parcial da função em relação a X). Para não entrar em muitos detalhes, vamos tentar exemplificar o caso, imaginando uma rede igual à do desenho: três entradas, quatro neurônios na camada oculta, e duas saídas. A função de custo para um único exemplo é (imaginando que “y1” é a saída desejada do neurônio “c1”):

Para achar o valor que MAXIMIZA a função para um determinado peso, por exemplo, o peso que liga o neurônio “b1” ao “c1” (peso_b1_c1), precisamos calcular a derivada parcial dele em relação à função de custo.
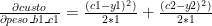
SÓ QUE a função de custo não possui o peso_b1_c1. Logo, vamos expandir a função:
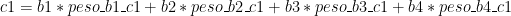
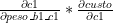
Logo (nota: estou mantendo o (1) porque quero deixar explícito que temos apenas um exemplo):


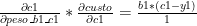
Um monte de coisa aconteceu aqui, mas vamos tentar explicar de uma maneira que não exija muita matemática: queremos achar o gradiente para o neurônio de saída c1. Mas, para isso, precisamos ver quais são os elementos que influenciam a saída de “c1”, e são eles: TODOS os nós da camada anterior (b1, b2, b3, e b4), mais os pesos de cada um desses neurônios (peso_b1_c1, peso_b2_c1, peso_b3_c1, e peso b4_c1). Certo, mas não podemos diretamente mexer no valores que estão nos neurônios anteriores-o que podemos mexer é no peso sináptico destes neurônios, que ligam-os ao neurônio “c1”. Para tal, precisamos saber quanto cada um destes pesos influencia no resultado, e tentar achar o gradiente. Sabemos que, achando o gradiente, se caminharmos em sua direção, vamos ter o valor que MAXIMIZA a função de custo, logo basta caminhar no sentido contrário. Certo, para calcular o gradiente, precisamos calcular uma derivada parcial da função de custo em relação à variável que queremos alterar para esta minimização/maximização. No exemplo acima, optei por começar a partir do peso que sai de “b1” e vai para “c1” (peso_b1_c1). A função de custo não possui essa variável, portanto expandimos a “c1” para vermos se a variável “peso_b1_c1” aparece nela. De fato, aparece, então podemos parar por aí. Nas contas também, nota-se que apenas adicionamos os elementos que influenciavam no resultado daquele peso-não faz sentido calcular derivada parcial para o peso_b2_c1, se estamos atualizando o peso_b1_c1. Por fim, quando expandimos o cálculo da derivada parcial, fizemos da seguinte maneira: a “derivada parcial da função de custo em relação a peso_b1_c1” é a mesma coisa que a “derivada parcial da função que calcula c1, em relação a peso_b1_c1, multiplicada pela derivada parcial da função de custo em relação a c1”.
Certo, mas calcular tudo isso para cada peso, e para todos os exemplos, nosso código ficaria muito complexo… uma saída é, novamente, a multiplicação de matrizes! Por exemplo, no caso abaixo, imaginemos nossa rede neural que fizemos no post anterior, no método abaixo:
def predict(input, input_weights, hidden_weights) hidden_layer_input = calculate_neuron_activation(input, input_weights) calculate_neuron_activation(hidden_layer_input, hidden_weights) end
A “hidden_layer_input” é o padrão que sai após a multiplicação dos neurônios “a” pelos pesos. Repare que não temos “peso_a1_b1”, pois “b1” é o neurônio “bias”. Para simplificar, vamos usar o nome “h” para estas saídas


Cada linha da matriz acima é um exemplo. Vamos imaginar que temos apenas dois exemplos, para deixar mais fácil a conta. Também, para facilitar a notação, vamos usar “b1”, “b2”, ao invés de “h1”, “h2”, etc.
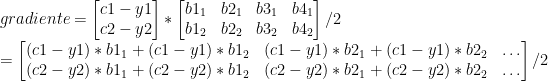
A única coisa é que no nosso exemplo, as linhas e colunas estão invertidas, então basta transpor a matriz final, e teremos nosso gradiente pronto. Como é possível ver, cada elemento da matriz é o gradiente que calculamos (uma média de todos os exemplos). Logo, o cálculo do gradiente para todos os exemplos (do neurônio de saída), continuando nosso código anterior, será:
#Lembrando: output_matrix é a matriz que preparamos, com os dados já classificados
def calculate_gradient(input, input_weights, hidden_weights, output_matrix)
hidden_layer_input = calculate_neuron_activation(input, input_weights)
output = calculate_neuron_activation(hidden_layer_input, hidden_weights)
#Custo desta solução:
size = output_matrix.row_count
error = output - output_matrix
squared_error = error.map { |e| e * e }
mean_squared_error = squared_error.to_a.flatten.inject(0) { |r, e| r + e } / (2 * row_count)
#Cálculo dos gradientes
hidden_layer_input_with_bias = hidden_layer_input.to_a.map { |x| [1] + x }
hidden_layer_input_with_bias = Matrix[*hidden_layer_input_with_bias]
gradient1 = (error.transpose * hidden_layer_input_with_bias).transpose / size
end
Com isto, o primeiro gradiente está calculado. Podemos atualizar os pesos da camada oculta (hidden_weights) usando estes pesos (obviamente, subtraindo ao invés de somando os valores, já que queremos minimizar a função de custo). Porém, ainda faltam os pesos da camada de entrada, que será mencionada na terceira parte deste post.
Para saber mais:
4 Comments
Humberto · 2013-04-04 at 15:05
Olá mauricio.gostei muito desse seu post.
Eu gostaria de montar uma rede neural
Maurício Szabo · 2013-04-09 at 11:08
Acompanhe o resto dos posts sobre rede neural, no final eu mostro o código completo sobre o assunto!
Humberto · 2013-04-12 at 09:53
ok!!
jaws · 2015-01-24 at 13:57
rapaz!
se isso é “for dummies”, imagine o “for experts”.
obrigado pelo tutorial está me ajudando muito.
Comments are closed.